转摘Pytorch实现GraphConv(基于PyTorch实现)
文章目录
前言
大家好,我是阿光。
本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现),理论与实践相结合,如GCN、GAT、GraphSAGE等经典图网络,每一个代码实例都附带有完整的代码。
正在更新中~ ✨

🚨 我的项目环境:
- 平台:Windows10
- 语言环境:python3.7
- 编译器:PyCharm
- PyTorch版本:1.11.0
- PyG版本:2.1.0
💥 项目专栏:[【图神经网络代码实战目录】](https://weibaohang.blog.csdn.net/article/details/128738325)
本文我们将使用PyTorch来简易实现一个GraphConv,不使用PyG库,让新手可以理解如何PyTorch来搭建一个简易的图网络实例demo。
一、导入相关库
本项目是采用自己实现的GraphConv,并没有使用 PyG 库,原因是为了帮助新手朋友们能够对GraphConv的原理有个更深刻的理解,如果熟悉之后可以尝试使用PyG库直接调用 GraphConv 这个图层即可。
prism language-python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.utils import scatter
from torch_geometric.datasets import Planetoid二、加载Cora数据集
本文使用的数据集是比较经典的Cora数据集,它是一个根据科学论文之间相互引用关系而构建的Graph数据集合,论文分为7类,共2708篇。
- Genetic_Algorithms
- Neural_Networks
- Probabilistic_Methods
- Reinforcement_Learning
- Rule_Learning
- Theory
这个数据集是一个用于图节点分类的任务,数据集中只有一张图,这张图中含有2708个节点,10556条边,每个节点的特征维度为1433。
prism language-python
# 1.加载Cora数据集
dataset = Planetoid(root='./data/Cora', name='Cora')三、定义GraphConv网络
3.1 定义GraphConv层
这里我们就不重点介绍GraphConv网络了,相信大家能够掌握基本原理,本文我们使用的是PyTorch定义网络层。
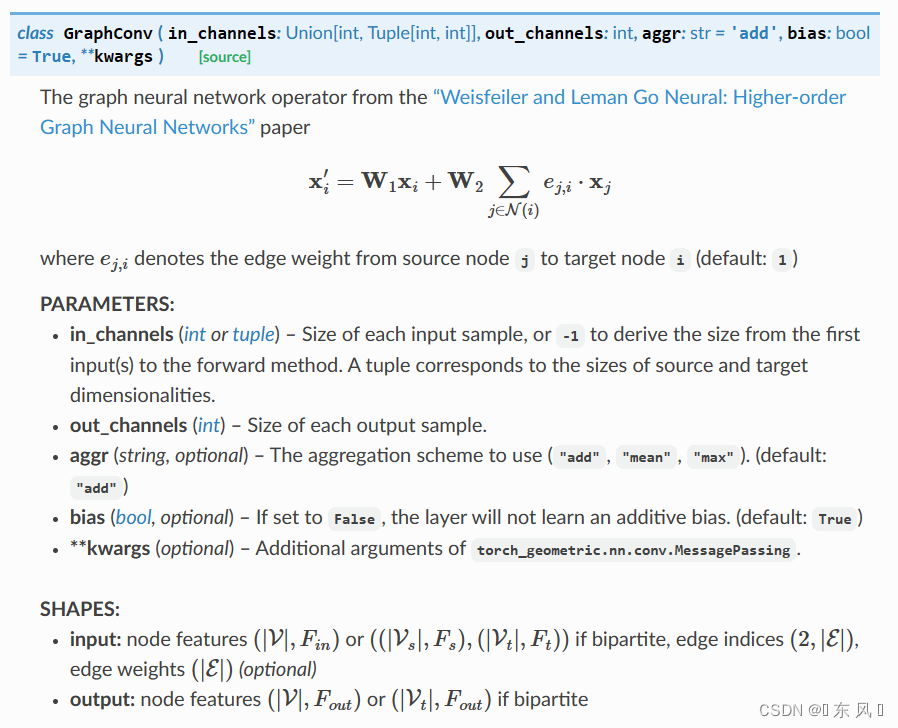
对于GraphConv的常用参数:
- in_channels:每个样本的输入维度,就是每个节点的特征维度
- out_channels:经过
GraphConv后映射成的新的维度,就是经过GraphConv后每个节点的维度长度 - aggr:对于邻居节点采用的聚合方式,默认为
add - bias:训练一个偏置b
我们在实现时也是考虑这几个常见参数
对于 GraphConv 的传播公式为:
x i ′ = W 1 x i + W 2 ∑ j ∈ N ( i ) e j , i x j x_i'=W_1x_i+W_2\sum_{j \in N(i)}e_{j,i}x_j xi′=W1xi+W2j∈N(i)∑ej,ixj
上式中的 x i x_i xi 代表 target 中心节点特征, x_j 代表 source 邻居节点特征,对于 W 1 W_1 W1 和 W 2 W_2 W2 代表每个 GraphConv 层的可学习参数, e j , i e_{j,i} ej,i 代表边的权重信息,本项目中默认为1。
所以我们的任务无非就是获取这几个变量,然后进行传播计算即可
3.1.1 定义权重 W
对于公式中有两个权重系数,分别是 W_1 和 W_2 ,所以我们要定义这两个可学习参数,为了方便,我们可以直接定义一个 Linear 层来表示特征映射,也可以使用最原始的方式 nn.Parameter(torch.randn(in_channels, out_channels)) 来定义权重系数,不过使用第一种方式方便一些,二者没有什么区别。
prism language-python
# 线性层
self.w1 = pyg_nn.dense.linear.Linear(in_channels, out_channels, weight_initializer='glorot', bias=bias)
self.w2 = pyg_nn.dense.linear.Linear(in_channels, out_channels, weight_initializer='glorot', bias=bias)3.1.2 特征映射
公式中存在两个特征映射的地方,分别是 W 1 x i W_1x_i W1xi 和 W 2 ⋅ m e a n j ∈ N ( i ) x j W_2·mean_{j \in N(i)}x_j W2⋅meanj∈N(i)xj,对于第一个实现起来较为简单,主要是第二个特征映射,它是先对所有邻居节点特征进行求和,然后再乘以 W 2 W_2 W2 进行特征映射。
prism language-python
# 对自身节点进行特征映射
wh_1 = self.w1(x)
# 获取邻居特征
x_j = x[edge_index[0]]
# 对邻居节点进行聚合
x_j = scatter(src=x_j, index=edge_index[1], dim=0, reduce='sum') # sum聚合操作 [num_nodes, out_channels]
# 对邻居节点进行特征映射
wh_2 = self.w2(x_j)3.1.3 节点特征更新
上面我们已经把两个特征映射后的结果计算出来,然后将二者相加直接返回即可:
prism language-python
return wh_1 + wh_23.1.4 GraphConv层
接下来就可以定义GraphConv层了,该层实现了1个函数,分别是forward()
forward():这个函数定义模型的传播过程,也就是上面公式的 x i ′ = W 1 x i + W 2 ∑ j ∈ N ( i ) e j , i x j x_i'=W_1x_i+W_2\sum_{j \in N(i)}e_{j,i}x_j xi′=W1xi+W2∑j∈N(i)ej,ixj,如果设置了偏置在加上偏置返回即可
prism language-python
# 2.定义GraphConv层
class GraphConv(nn.Module):
def __init__(self, in_channels, out_channels, bias=True):
super(GraphConv, self).__init__()
# 线性层
self.w1 = pyg_nn.dense.linear.Linear(in_channels, out_channels, weight_initializer='glorot', bias=bias)
self.w2 = pyg_nn.dense.linear.Linear(in_channels, out_channels, weight_initializer='glorot', bias=bias)
def forward(self, x, edge_index):
# 对自身节点进行特征映射
wh_1 = self.w1(x)
# 获取邻居特征
x_j = x[edge_index[0]]
# 对邻居节点进行聚合
x_j = scatter(src=x_j, index=edge_index[1], dim=0, reduce='sum') # sum聚合操作 [num_nodes, out_channels]
# 对邻居节点进行特征映射
wh_2 = self.w2(x_j)
return wh_1 + wh_2对于我们实现这个网络的实现效率上来讲比PyG框架内置的 GraphConv 层稍差一点,因为我们是按照公式来一步一步利用矩阵计算得到,没有对矩阵计算以及算法进行优化,不然初学者可能看不太懂,不利于理解GraphConv公式的传播过程,有能力的小伙伴可以看下官方源码学习一下。
3.2 定义GraphConv网络
上面我们已经实现好了 GraphConv 的网络层,之后就可以调用这个层来搭建 GraphConv 网络。
prism language-python
# 3.定义GraphConv网络
class Model(nn.Module):
def __init__(self, num_node_features, num_classes):
super(Model, self).__init__()
self.conv1 = GraphConv(num_node_features, 16)
self.conv2 = GraphConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)上面网络我们定义了两个 GraphConv 层,第一层的参数的输入维度就是初始每个节点的特征维度,输出维度是16。
第二个层的输入维度为16,输出维度为分类个数,因为我们需要对每个节点进行分类,最终加上softmax操作。
四、定义模型
下面就是定义了一些模型需要的参数,像学习率、迭代次数这些超参数,然后是模型的定义以及优化器及损失函数的定义,和pytorch定义网络是一样的。
prism language-python
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
epochs = 10 # 学习轮数
lr = 0.003 # 学习率
num_node_features = dataset.num_node_features # 每个节点的特征数
num_classes = dataset.num_classes # 每个节点的类别数
data = dataset[0].to(device) # Cora的一张图
# 3.定义模型
model = Model(num_node_features, num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 优化器
loss_function = nn.NLLLoss() # 损失函数五、模型训练
模型训练部分也是和pytorch定义网络一样,因为都是需要经过前向传播、反向传播这些过程,对于损失、精度这些指标可以自己添加。
prism language-python
# 训练模式
model.train()
for epoch in range(epochs):
optimizer.zero_grad()
pred = model(data)
loss = loss_function(pred[data.train_mask], data.y[data.train_mask]) # 损失
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item() # epoch正确分类数目
acc_train = correct_count_train / data.train_mask.sum().item() # epoch训练精度
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print("【EPOCH: 】%s" % str(epoch + 1))
print('训练损失为:{:.4f}'.format(loss.item()), '训练精度为:{:.4f}'.format(acc_train))
print('【Finished Training!】')六、模型验证
下面就是模型验证阶段,在训练时我们是只使用了训练集,测试的时候我们使用的是测试集,注意这和传统网络测试不太一样,在图像分类一些经典任务中,我们是把数据集分成了两份,分别是训练集、测试集,但是在Cora这个数据集中并没有这样,它区分训练集还是测试集使用的是掩码机制,就是定义了一个和节点长度相同纬度的数组,该数组的每个位置为True或者False,标记着是否使用该节点的数据进行训练。
prism language-python
# 模型验证
model.eval()
pred = model(data)
# 训练集(使用了掩码)
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item()
acc_train = correct_count_train / data.train_mask.sum().item()
loss_train = loss_function(pred[data.train_mask], data.y[data.train_mask]).item()
# 测试集
correct_count_test = pred.argmax(axis=1)[data.test_mask].eq(data.y[data.test_mask]).sum().item()
acc_test = correct_count_test / data.test_mask.sum().item()
loss_test = loss_function(pred[data.test_mask], data.y[data.test_mask]).item()
print('Train Accuracy: {:.4f}'.format(acc_train), 'Train Loss: {:.4f}'.format(loss_train))
print('Test Accuracy: {:.4f}'.format(acc_test), 'Test Loss: {:.4f}'.format(loss_test))七、结果
prism language-python
【EPOCH: 】1
训练损失为:5.8066 训练精度为:0.1500
【EPOCH: 】21
训练损失为:1.6594 训练精度为:0.3429
【EPOCH: 】41
训练损失为:1.1806 训练精度为:0.5357
【EPOCH: 】61
训练损失为:0.9731 训练精度为:0.6929
【EPOCH: 】81
训练损失为:0.8660 训练精度为:0.7214
【EPOCH: 】101
训练损失为:0.6059 训练精度为:0.8786
【EPOCH: 】121
训练损失为:0.6301 训练精度为:0.8643
【EPOCH: 】141
训练损失为:0.4670 训练精度为:0.9143
【EPOCH: 】161
训练损失为:0.4780 训练精度为:0.8786
【EPOCH: 】181
训练损失为:0.3472 训练精度为:0.9429
【Finished Training!】
>>>Train Accuracy: 0.9929 Train Loss: 0.2319
>>>Test Accuracy: 0.6030 Test Loss: 1.2378| 训练集 | 测试集 | |
|---|---|---|
| Accuracy | 0.9929 | 0.6030 |
| Loss | 0.2319 | 1.2378 |
完整代码
prism language-python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.utils import scatter
import torch_geometric.nn as pyg_nn
from torch_geometric.datasets import Planetoid
# 1.加载Cora数据集
dataset = Planetoid(root='./data/Cora', name='Cora')
# 2.定义GraphConv层
class GraphConv(nn.Module):
def __init__(self, in_channels, out_channels, bias=True):
super(GraphConv, self).__init__()
# 线性层
self.w1 = pyg_nn.dense.linear.Linear(in_channels, out_channels, weight_initializer='glorot', bias=bias)
self.w2 = pyg_nn.dense.linear.Linear(in_channels, out_channels, weight_initializer='glorot', bias=bias)
def forward(self, x, edge_index):
# 对自身节点进行特征映射
wh_1 = self.w1(x)
# 获取邻居特征
x_j = x[edge_index[0]]
# 对邻居节点进行聚合
x_j = scatter(src=x_j, index=edge_index[1], dim=0, reduce='sum') # sum聚合操作 [num_nodes, out_channels]
# 对邻居节点进行特征映射
wh_2 = self.w2(x_j)
return wh_1 + wh_2
# 3.定义GraphConv网络
class Model(nn.Module):
def __init__(self, num_node_features, num_classes):
super(Model, self).__init__()
self.conv1 = GraphConv(num_node_features, 16)
self.conv2 = GraphConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
epochs = 200 # 学习轮数
lr = 0.0003 # 学习率
num_node_features = dataset.num_node_features # 每个节点的特征数
num_classes = dataset.num_classes # 每个节点的类别数
data = dataset[0].to(device) # Cora的一张图
# 4.定义模型
model = Model(num_node_features, num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 优化器
loss_function = nn.NLLLoss() # 损失函数
# 训练模式
model.train()
for epoch in range(epochs):
optimizer.zero_grad()
pred = model(data)
loss = loss_function(pred[data.train_mask], data.y[data.train_mask]) # 损失
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item() # epoch正确分类数目
acc_train = correct_count_train / data.train_mask.sum().item() # epoch训练精度
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print("【EPOCH: 】%s" % str(epoch + 1))
print('训练损失为:{:.4f}'.format(loss.item()), '训练精度为:{:.4f}'.format(acc_train))
print('【Finished Training!】')
# 模型验证
model.eval()
pred = model(data)
# 训练集(使用了掩码)
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item()
acc_train = correct_count_train / data.train_mask.sum().item()
loss_train = loss_function(pred[data.train_mask], data.y[data.train_mask]).item()
# 测试集
correct_count_test = pred.argmax(axis=1)[data.test_mask].eq(data.y[data.test_mask]).sum().item()
acc_test = correct_count_test / data.test_mask.sum().item()
loss_test = loss_function(pred[data.test_mask], data.y[data.test_mask]).item()
print('Train Accuracy: {:.4f}'.format(acc_train), 'Train Loss: {:.4f}'.format(loss_train))
print('Test Accuracy: {:.4f}'.format(acc_test), 'Test Loss: {:.4f}'.format(loss_test)) ===========================
【来源: CSDN】
【作者: 海洋.之心】
【原文链接】 https://weibaohang.blog.csdn.net/article/details/128823065
声明:转载此文是出于传递更多信息之目的。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本网联系,我们将及时更正、删除,谢谢。